Robots.txt on ohjetiedosto, jonka tarkoitus on antaa hakukoneiden hakuroboteille ohjeita siitä, mitä sivuston osia ne saavat tai eivät saa crawlaa (eli käydä läpi ja lukea). Oikein käytettynä se voi parantaa sivuston indeksoinnin laatua, säästää palvelimen kuormaa ja auttaa hakukoneita keskittymään niihin sivuihin, joilla on oikeasti merkitystä.
Tässä artikkelissa käydään läpi:
- Mikä on robots.txt?
- Miksi robots.txt on tärkeä?
- Robots.txt:n perusrakenne selkokielellä
- Miten tarkistaa robots.txt:n?
- Robots.txt tietoturvan näkökulmasta
- Miten määritellä robots.txt:n sisällön käytännössä?
- Usein kysytyt kysymykset
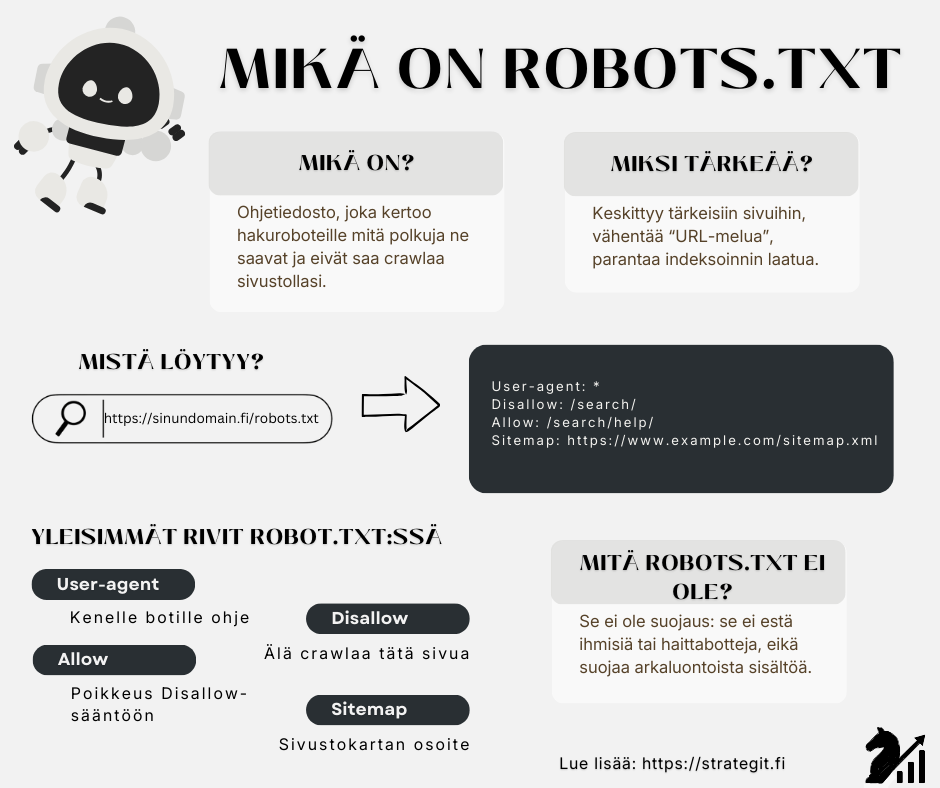
Mikä on robots.txt?
Robots.txt on tekstitiedosto, joka sijaitsee yleensä sivustosi juuriosoitteessa:
https://sinundomain.fi/robots.txt
Se sisältää “sääntöjä” boteille (esim. hakukoneiden indeksoijille ja muille automaattisille ohjelmille), kuten:
- mitä polkuja ne saavat käydä läpi
- mitä polkuja niiden toivotaan jättävän rauhaan
Robots.txt voi verrata taloyhtiön ilmoitustauluun, jossa lukee “älä jätä pyöriä tähän”. Kaikki eivät välttämättä noudata näitä ohjeita.
Miksi robots.txt on tärkeä?
Tärkeä sisältö ei jää varjoon
Hakukoneiden botit eivät kierrä sivustoja rajattomasti. Niillä on käytännössä rajallinen “aika ja huomio” per sivusto (Crawl budget), ja jos sivustollasi on paljon URL-osoitteita, botti voi käyttää ison osan crawlauksesta asioihin, joilla ei ole hakunäkyvyyden kannalta mitään arvoa. Tätä tapahtuu erityisesti silloin, kun sivuja on paljon, kun sivusto tuottaa automaattisesti “turhia” URL:eja (esim. hakutulossivut, suodattimet, tagiarkistot) tai kun sama sisältö toistuu useina versioina (tuplasisällön riski).
Lopputulos on yksinkertainen: tärkeät sivut – kuten palvelut, tuotteet ja parhaat blogiartikkelit – voivat indeksoitua hitaammin tai jäädä vähemmälle huomiolle.
Pienellä sivustolla tärkeintä on perusasiat
Pienellä tai keskikokoisella sivustolla crawl budget ei yleensä ole ensimmäinen ongelma, mutta perusasiat kannattaa silti pitää kunnossa. Käytännössä tämä tarkoittaa, että
- sivustokartta on ajan tasalla
- seuraat että tärkeät sivut indeksoituvat
- vältät turhia tai tupla-URL:eja (hakusivut, parametrisivut, vanhat poistuneet sivut ilman selkeitä ohjauksia). Robots.txt on yksi työkalu, jolla tätä “URL-melua” voi hallita.
Keventää palvelimen kuormaa
Robots.txt vaikuttaa myös palvelimen kuormaan. Kun botteja ohjataan pois reiteiltä, joilla ei ole hyötyä (tai joita ei haluta crawlatuksi), sivusto saa vähemmän turhia pyyntöjä. Tämä korostuu erityisesti jaetuissa hosting-ympäristöissä sekä tilanteissa, joissa bottiliikennettä on paljon – myös uudemmat tekoälyindeksoijat voivat kuormittaa palvelinta yllättävän voimakkaasti.
Parantaa indeksoinnin laatua
Lopulta tärkein hyöty on indeksoinnin laatu. Kun hakukone näkee sivustosta vähemmän “roinaa” ja enemmän selkeää, tarkoituksenmukaista sisältöä, sivuston kokonaiskuva paranee: hakukoneen on helpompi ymmärtää, mitkä sivut ovat olennaisimmat ja mihin ne kannattaa nostaa näkyvyyttä.
Robots.txt:n perusrakenne selkokielellä
Robots-tiedostossa yleisimmät rivit ovat:
User-agent:kenelle bottityypille ohje annetaanDisallow:mitä polkua pyydetään olemaan crawlaamattaAllow:poikkeus (sallitaan jokin tarkempi polku, vaikka ylempi olisi estetty)Sitemap:mistä löytyy sivustokartta
Hakukoneet valitsevat bottia varten parhaiten täsmäävän (yleensä “tarkimman”) user-agent -ryhmän. Jos sama user-agent on määritelty useassa ryhmässä, säännöt yhdistetään.
Esimerkkipohja (älä kopioi sellaisenaan):
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /search/
Sitemap: https://sinundomain.fi/sitemap.xml
Mitä tämä tekee?
- koskee kaikkia botteja (
User-agent: *) - pyytää botteja pysymään poissa WordPressin hallinnasta ja tietyistä poluista
- pyytää botteja olemaan crawlaamatta, jotka voivat paisuttaa URL-massaa
- kertoo mistä löytyy sivustokartta
Huom: WordPress-sivukartta voi olla esim.
/sitemap_index.xmltai/sitemap.xmlriippuen käytössä olevista lisäosista.
Miten tarkistaa robots.txt:n?
- Avaa selaimessa:
https://sinundomain.fi/robots.txt - Tarkista 3 asiaa:
- Onko tiedosto olemassa?
- Näkyykö siellä vahingossa esto koko sivustolle (
Disallow: /)? - Onko siinä “salaisia” polkuja, joita et haluaisi mainostaa julkisesti?
- Jos käytät Google Search Consolea, voit testata robots-sääntöjen vaikutusta ja nähdä, indeksoiko Google tärkeitä sivuja oikein. Vastaava työkalu löytyy myös Bing Webmaster Tools -puolelta Bingille.
Robots.txt tietoturvan näkökulmasta
Robots.txt ei ole tapa “piilottaa” sisältöä. Robots.txt:
- ei estä ihmistä avaamasta URL-osoitetta selaimessa
- ei estä haitallisia botteja (ne voivat ohittaa sen)
- on julkinen tiedosto, jota kuka tahansa voi lukea
Jos haluat pitää sisällön pois hakutuloksista, riippuen sisällöstä käytä mieluummin:
noindex-merkintää (meta-tagilla tai HTTP-headerilla) ja varmista, ettei sivua ole estetty robots.txt:llä. Jos sivu on estetty robots.txt:llä (tai botti ei muuten pääse sivulle), hakukone ei näe noindex-merkintää ja URL voi silti näkyä hakutuloksissa esimerkiksi linkkien perusteella.- tai suojaa sisältö kirjautumisella / salasanalla
- tai poista sisältö kokonaan julkisesta ympäristöstä
Miten määritellä robots.txt:n sisällön käytännössä?
Aloita strategiasta: mitä haluat hakutuloksissa näkyvän?
Yleinen harhaluulo on, että “mitä enemmän sivuja näkyy, sitä parempi”. Usein totuus on päinvastainen.
Tuplasisältö heikentää niin hakukonenäkyvyyttä että käyttäjäkokemusta, koska se pakottaa hakukoneen arvailemaan, mikä sivun versio on tärkein sekä käyttäjiä päätymään väärälle sivulle. Kun sama (tai lähes sama) sisältö löytyy useista URL-osoitteista (esim. suodatetut listaukset, tagit ja kategoriat) sivut alkavat kilpailla keskenään samoista hakusanoista (näkyvyys hajoaa eikä mikään sivu nouse vahvaksi)
Tavoite ei ole maksimoida sivujen määrä hakutuloksissa.
Tavoite on varmistaa, että hakutuloksissa näkyvät oikeat sivut.
Mieti ensin: “Mitä haluan asiakkaan löytävän?”
Tyypillinen “hyvä näkyvyys” -lista on:
- Etusivu
- Palvelusivut / tuotesivut
- Yhteystiedot
- Blogiartikkelit
- Referenssit / case-sivut (jos käytössä)
Tarkista seuraavaksi, syntyykö sivustollesi “turhia” hakutulos-URL:eja.
Katso erityisesti:
- Filtterit ja järjestelyt verkkokaupassa (väri, koko, hinta, sorttaus jne.)
- Tägit (tag-arkistot)
- Kategoriat (category-arkistot)
Testaa käytännössä: klikkaa filttereitä ja seuraa URL-osoitetta.
- Mene tuotteisiin/tuotekategoriaan tai listaukseen
- Klikkaa filtteriä (esim. “musta”, “koko M”, “halvin ensin”)
- Katso, muuttuuko URL ja tuleeko siihen esim. merkkejä kuten
?ja&- Esim.
?color=black&size=m&sort=price
- Esim.
Kopioi URL:sta se osa, joka toistuu kaikissa suodatuksissa.
Tavoite on tunnistaa, mikä tekee suodatetuista sivuista erilaisia URL:eja, esimerkiksi:
/tag/tai/category//search/tai?s=- parametrit kuten
?filter=/?sort=/?page=
Lisää rajaus robots.txt:ään vasta, kun tiedät mitä olet rajaamassa.
Robots.txt-rajauksessa käytetään yleensä polkua (ei koko domainia), eli esimerkiksi:
- estä hakusivut:
Disallow:/search/taiDisallow:/?s= - estä tagit:
Disallow:/tag/ - estä kategoriat:
Disallow:/category/ - estä tietosuojaseloste:
Tärkeä huomata, että “turha” SEO:n kannalta ei tarkoita, että sivu olisi turha käyttäjälle. Esimerkiksi tietosuojaseloste on käyttäjälle tärkeä, mutta se ei yleensä ole sivuston näkyvyyden veturi. Siksi sitä ei yleensä tarvitse “piilottaa” – mutta sitä ei myöskään tarvitse optimoida hakukoneelle muiden tärkeiden sivujen kustannuksella eikä välttämättä näyttää ollenkaan hakukoneen tuloksissa. Huom. Jos laitat robots.txt:ään esim. Disallow: /tietosuojaseloste/, Google voi silti joskus näyttää URL:n hakutuloksissa (ilman kuvausta), koska se tietää osoitteen linkkien kautta.
Lisää mieluummin tietosuojaselosteen sivulle:
<meta name="robots" content="noindex,follow">- noindex = älä näytä hakutuloksissa
- follow = hakukone saa silti seurata linkkejä (yleensä ok)
Älä kuitenkaan tee laajoja estoja “varmuuden vuoksi” (esim. kokonaisia kansioita), jos et tiedä vaikutusta. Liian laaja esto voi estää hakukonetta näkemästä sivua oikein tai blokata vahingossa tärkeitä sivuja.
Usein kysytyt kysymykset
Ei luotettavasti. Robots.txt estää crawlausta, mutta URL voi silti näkyä hakutuloksissa ilman sisältöä/snippettiä. Jos haluat varmasti pois hakutuloksista, käytä noindex-merkintää tai suojaa sivu kirjautumisella. Muita kuitenkin varmistaa, ettei kyseistä sivua ole estetty robots.txt:llä. Jos sivu on estetty robots.txt:llä, hakukonebotti ei näe noindex-merkintää ja URL voi silti näkyä hakutuloksissa esimerkiksi linkkien perusteella.
Kyllä, jos estät vahingossa tärkeitä sivuja tai resursseja. Erityisesti liian laajat estot voivat estää hakukonetta ymmärtämästä sivua oikein.
Älä tee sitä robots.txt:llä. Lisää mieluummin sivulle:<meta name="robots" content="noindex,follow">
Näin sivu säilyy käyttäjälle luettavana, mutta se ei näy hakutuloksissa.
Hakukoneet välimuistittavat robots.txt:n, joten muutos ei aina näy heti. Siksi muutokset kannattaa testata Search Consolessa ja seurata indeksiraportteja. Voit myös yrittää nopeuttaa päivitystä pyytämällä Googlen uudelleenhakua tärkeille sivuille: Google Search Console → URL Inspection/URL-tarkistus → syötä tärkeä URL → Request indexing/Pyydä indeksointia. Tämä ei “pakota” Googlea tekemään kaikkea heti, mutta voi nopeuttaa sitä, että Google käy tarkistamassa sivun tilanteen ja päivittää tietojaan.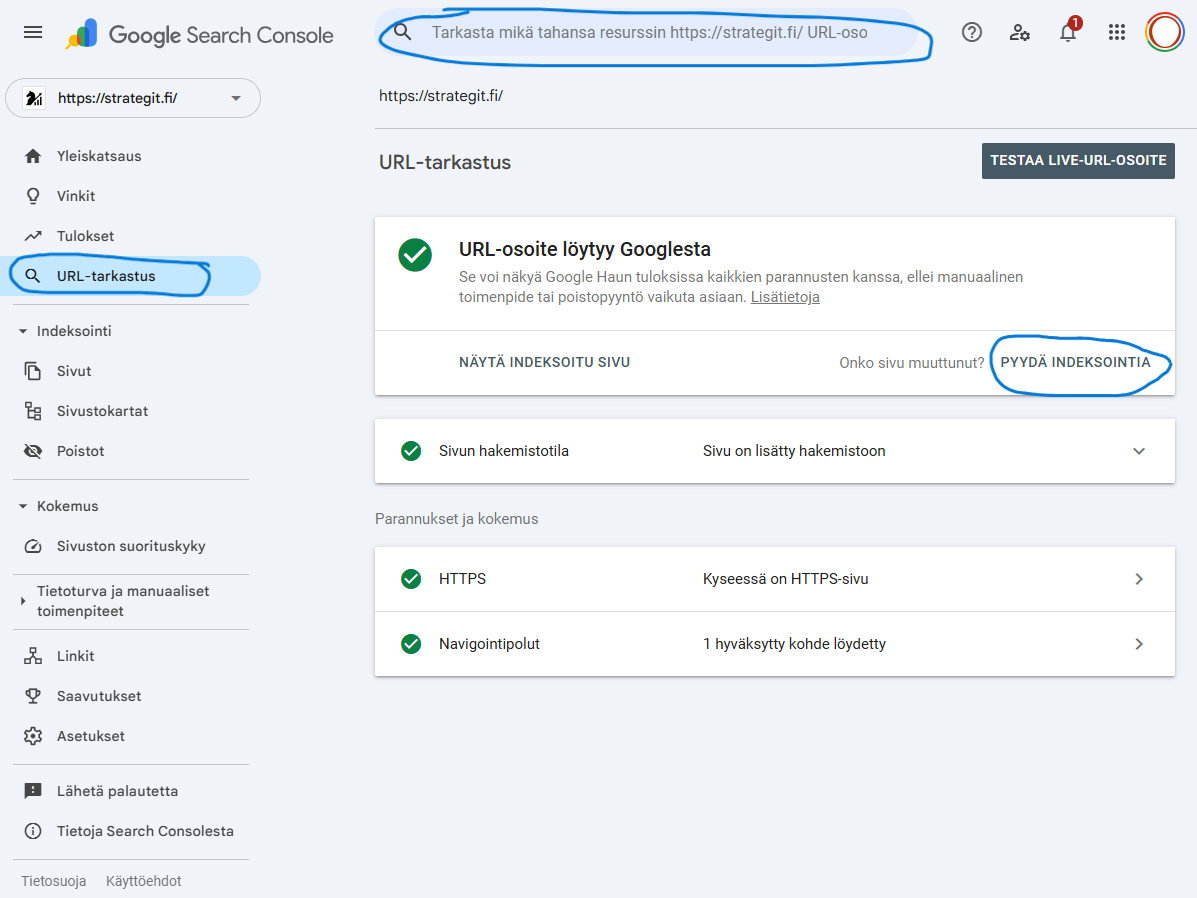
Ei. Robots.txt on hakukoneille tarkoitettu ohje, ei pääsynhallinta. Kuka tahansa voi avata URL-osoitteen selaimessa, ja haitalliset botit voivat ohittaa robots.txt:n. Lisäksi robots.txt on julkinen tiedosto, joten se paljastaa “piilottamasi” polkuja.